
Towards Reliable Agentic Systems (Part 1) - Understanding Error
What software engineering can steal from the hard engineering & sciences about controlling error in systems

Note: This post has been sitting in my writing drafts for about a year, but i’ve only just gotten around to publishing it. Some of the information may be a bit out of date, but I’ve tried to keep the principles timeless. Hope you find it helpful
Historically, software engineering has been deterministic rule setting. If the code says “go left at traffic lights”, software will always go left at traffic lights—even if there is a brick wall. The job of software engineers is to build interacting rule-sets that handle what software will encounter in the wild, e.g., don’t go left if there is a brick wall.
In contrast, hard engineering problems have always had probability and tolerance to as constraints to design around. If I’m creating a circuit with 10 ohm resistors, it needs to work if the resistor 9.7 ohms or 10.3 ohms, because I buy ten thousand of them and the manufacturer only guarantees them to 3% of the sticker value.
Vibe coding and multi-agent systems can generate copious amounts of code. Through this they shift software engineering into a domain where tolerance and error correction needs to be handled when writing the high level systems. In this series of articles, we’ll try to:
build some intuition around how error propagates in agent systems
create frameworks for managing and controlling that error
define metrics to measure reliability and success.
Understanding the problem
Baseline vibe coding process is this:
User prompts for a change
AI agent processes and executes the change
Go to 1.
Anyone playing with LLMs have done this already. We quickly discover how AI agents will confidently create mountains of spaghetti code with errors that compound each iteration through the chat loop.
Control theory people (and circuit designers) will recognize this problem as a positive feedback loop. When a small amount of error is amplified, you quickly saturate to infinite error.
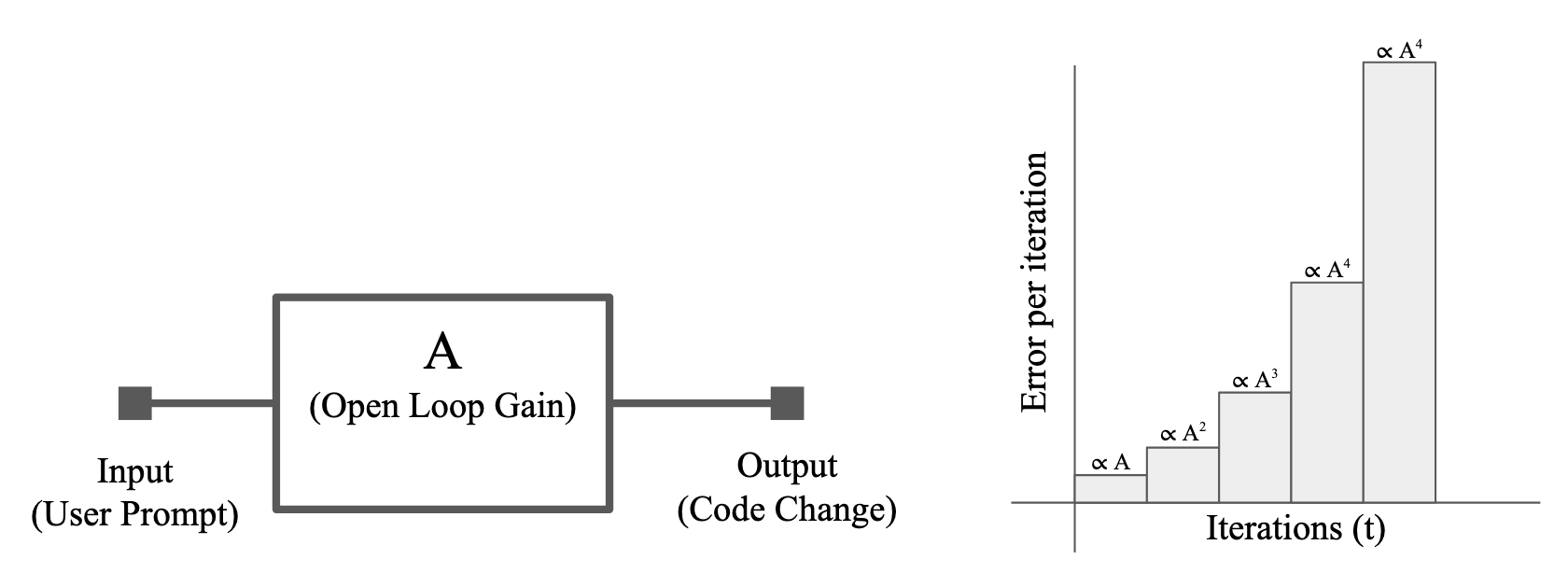
As illustrated in Figure 1, a simple vibe coding system will compound error at teach iteration. If we assume some open loop gain factor A, we can assume that error will grow proportionally to this gain factor. That means that we can express the total error E(t) as
where t is the total number of iterations, A is the gain factor. The bulk standard solution for this is negative feedback but before we get to that lets understand where error comes from how interacting agents will affect error.
Error comes from how the model thinks
Brief Illustrative Tangent - In a previous life, I worked on building AI systems (CV CNNs) for cancer detection in mammography. In Europe, every mammogram is read by at least two radiologists. If they disagree a third person reads and makes the final decision. If each person is correct 90% of the time, then together they will be correct 99% of the time.
In practice, however, the best places could only muster about ~92% correctness. Why? Well many reasons:
They see the same patient population with the same distribution of demographics, ethnicities, etc.
They saw first reader’s decision and so they got biased (←remember this)
Went to similar schools with similar standards, textbooks, and exams
Get tired the same way late at night and get really hangry around 11:30 am
Some party on the weekend and therefore have hangovers on Mondays or are distracted Friday night.
…
And a myriad of infinite reasons.
Different thinking → different mistakes (and different skills)
Upon deployment, we found something interesting. The algorithm worked completely differently to humans; it made different types of mistakes. Sometimes it found a cancer buried in the most fibrous hard to read area of the image (incredibly hard for radiologists). Other times it confused a pacemaker with cancer. The big takeaways here:
There are mistakes that AI makes that a human won’t.
There are mistakes humans make, that AI won’t.
All things being independent, a human-AI team will necessarily make fewer errors (see Figure 1).
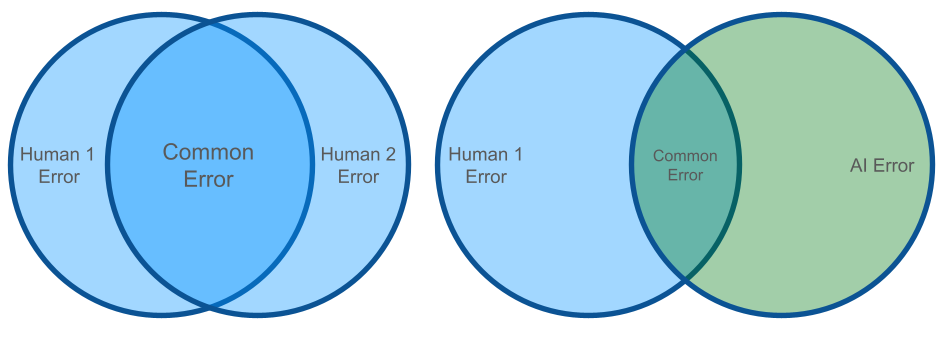
Note: this is idealized, but independence is a reasonable initial assumption to begin with when modeling.
Error in multi agent systems
This concept applies to multi-agent systems. We know that:
models are different architectures,
trained on different corpses of data,
have different methods for data generation and cleaning,
and ultimately are made by different people.
While there is considerable overlap between the models, the models fundamentally think differently and have different capabilities.
This implies that multi-agent systems can be leveraged to further reduce this error (see Figure 2). If all models have differing error, then multiple passes with agents will further constrain the error that gets through the system.
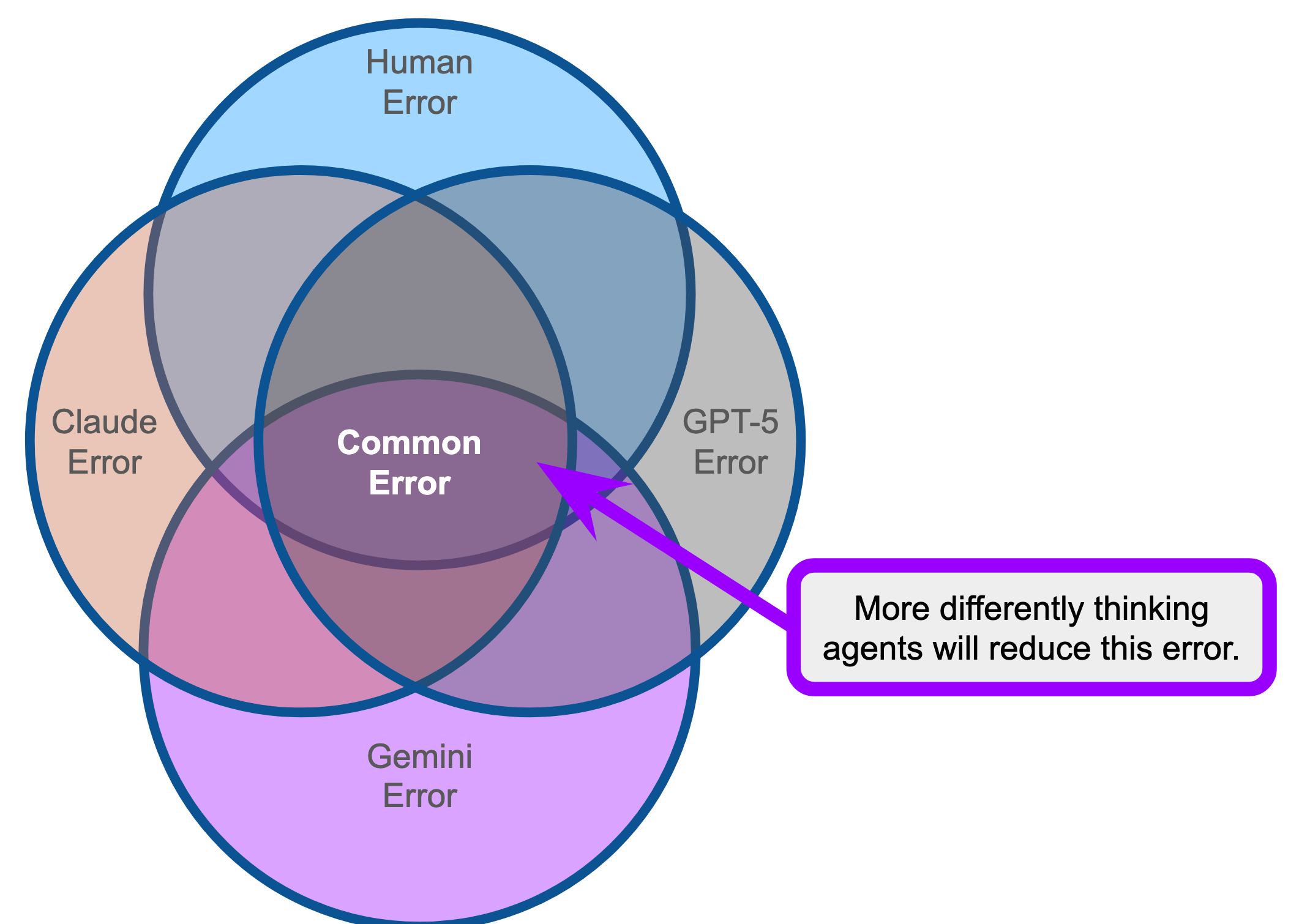
Importantly, AI models have roughly the same resources and operating speed, so our assumption of independence is even more true between AI agents then AI+Human teams, in a vacuum.
Role further changes error distribution
Taking this further, we can actually create multiple roles for each agent to further constrain error. When we ask a model to assume a role, we are fundamentally transforming the distribution of outputs from that model (see Figure 3). The baseline knowledge (data) is still there, but the model will 1) pay attention to different things, 2) have a different framework for prioritization, 3) generate different kinds of outputs.
Intuition: When I think about a security review in a codebase, I think ports, IP address, encryption, authentication, etc. Therefore, I’m less likely to find bugs with the database queries.
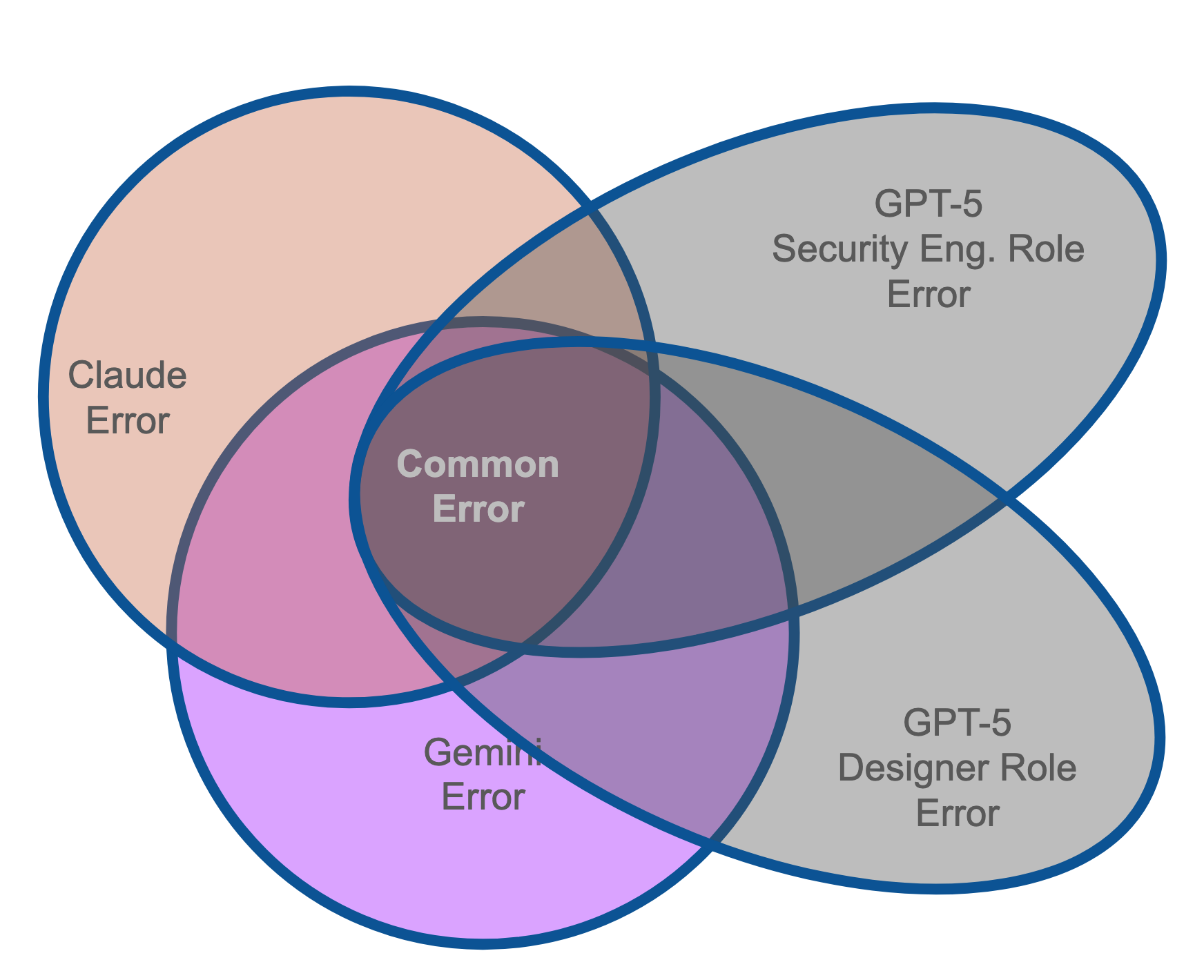
Agent-Agent Error vs Human-Agent Error - Humans are not really independent
Now lets talk about user+system error and address our idealized assumption of error independence. Truth is that its functionally impossible for a person to review at the level equivalent to an agent. A 200K context window for an agent is ~375 pages of text that an agent review in about 10-30s. Also, we humans like to minimize energy usage (laziness) so we will happily let the agent do most of the work. This necessarily means that human error is not statistically independent—human error will be shaped by the upstream transformation. So we need a better model for error propagation.
Going back to the mamography example, One of the largest sources of bias/error we found was when reader 2 had access to reader 1 result. The reader software was designed to avoid this, but when we actually went and visited the clinics, there was a folder pile of cases. Reader 2 would look at the folder pile to see the list of patients to review and clearly saw the reader 1 results. This bore out in the data as readers from that site were more likely to corroborate the decision compared to other mammography centers.
We also had another biasing issue when deploying our cancer detection software. In one experiment we “prioritized” the daily case pile such that the detected cancers would be at the top and this happened:
Easier cancers would be top of pile
Extremely hard to find cancers could be spread throughout the pile.
Readers would figure out the prioritization and apply more attention to the top of pile cases and flick through the rest much faster, thereby they were more likely to miss the really hard cases.
Productivity and overall detection rate improved, the difficult to detect cancers were negatively affected by user behavior.
Going back to our human multi-agent system, this implies faster development, but the errors that get through will be harder to solve—So we need to take a different strategy to find and fix these errors—better yet we need to control and shape the types of errors we will see.
End of Part 1
That’s it for Part 1. Hopefully you’ve gotten some intuition on how to think about reliability in multi-agent systems. Part 2 will discuss actual tools and feedback signals we can create and manage to improve agent systems.