
Towards Reliable Agentic Systems (Part 2) — Multiagent Patterns
How to coordinate multiple AI models without letting them fight each other
In Part 1, we looked at how error propagates across humans, agents, and multi-agent execution. More importantly, we explored how multi-model systems — Claude, Codex, and Gemini — don’t just vary in capability. They have distinct blind spots, reasoning styles, and default patterns. Used in concert, they compensate for each other’s weaknesses in ways that running three copies of the same model never will.
This article walks through the multiagent patterns I’ve been using to build stuff. Each controls error differently. Understanding why — not just how to set it up — help me choose the right ones. It’s a bit esoteric, but by the end we’ll get intuition for when to deploy each pattern, how information flows are shaped, and the general principles underneath.
Coding Patterns
Two Agents, One Codebase: The Oscillation Problem
The most obvious multiagent pattern is the one that breaks first: point two agents at the same project and let them both write code.
Agent A refactors a function signature. Agent B, working from a stale understanding, calls the old signature. Agent A “fixes” B’s call. Agent B reverts it. This is oscillation — agents undoing each other’s work in a loop, each convinced it’s making a correction.
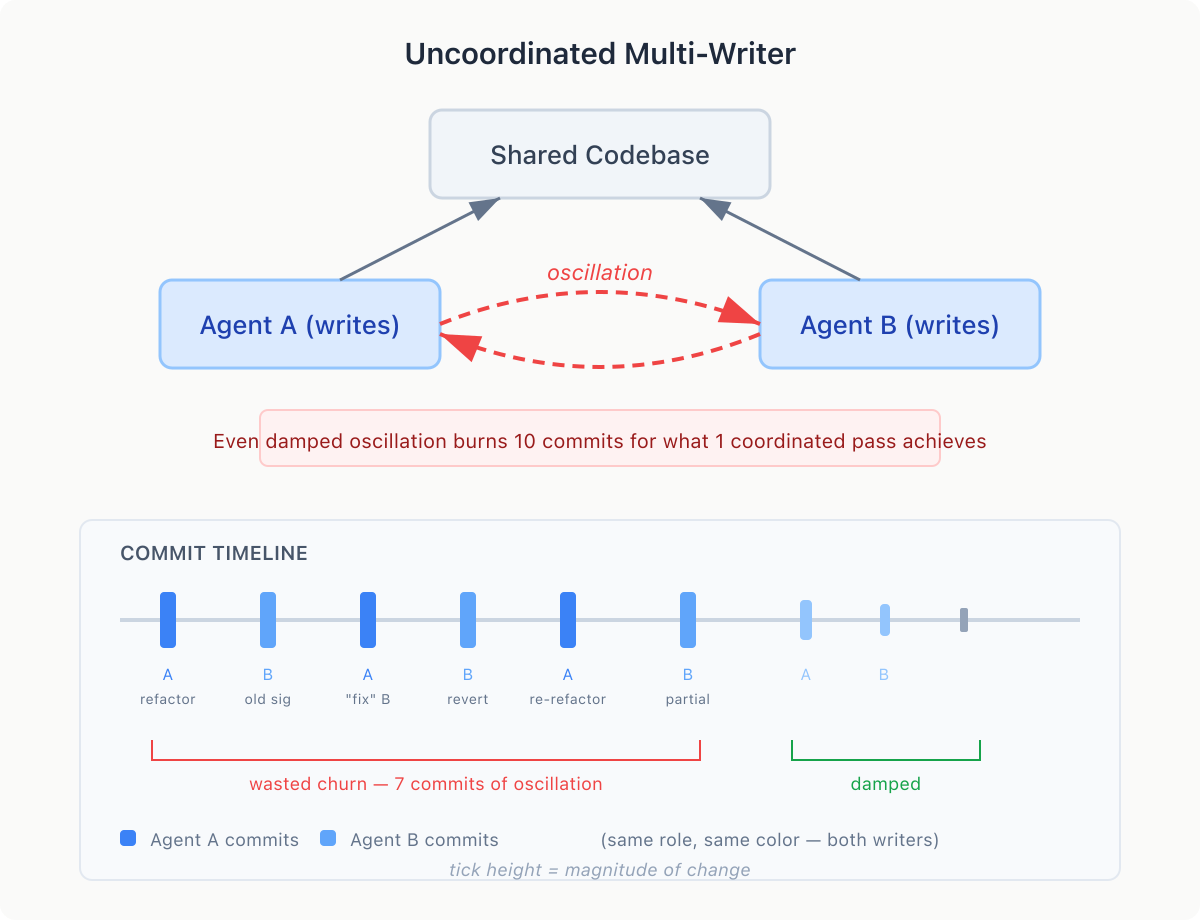
The root cause is shared state, disparate understanding, and independent decision-making. You discussed something with one agent, the other never got the memo. Often you get damped oscillation — the conflict eventually resolves, but only after many rounds of churn. Ten commits for what one coordinated pass would have accomplished. The code looks fine at the end. The commit history is noise. A smarter agent oscillates just as hard — it just writes more sophisticated reverts.
The Single-Writer Fix (peer-programming agents)
The oscillation error mode has one cause: two writers. The fix is simple: remove one.
Designate one agent as the writer and the other as a read-only reviewer. The writer produces code. The reviewer critiques it and returns feedback. Only one agent ever touches the file.
The reviewer returns GO or NO-GO with specifics. The writer loops until GO. Each pass addresses specific feedback, so issues shrink naturally. This is my workhorse — Claude implements a chunk, Codex reviews it, loop until we get a GO.
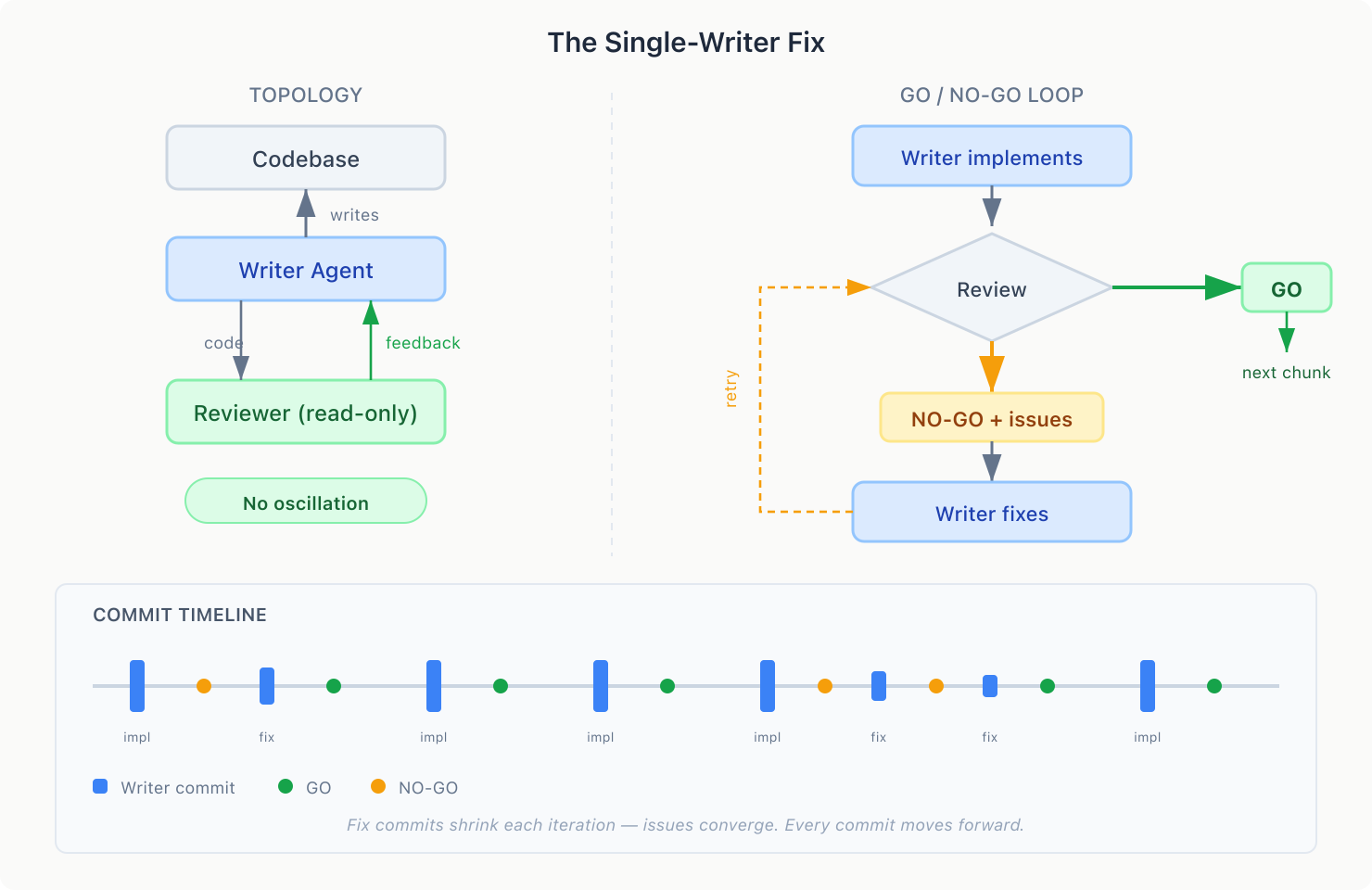
In practice, the writer will ignore the reviewer sometimes. “Codex wants change X, but we decided on Y with the human, ignoring....” This is mostly the system working — the writer has context the reviewer doesn’t.
Nothing limits you to one reviewer. My usual approach: in-flight peer-programming (Claude + Codex), then a PR review with a different model scoped to all changes (Gemini or Grok).
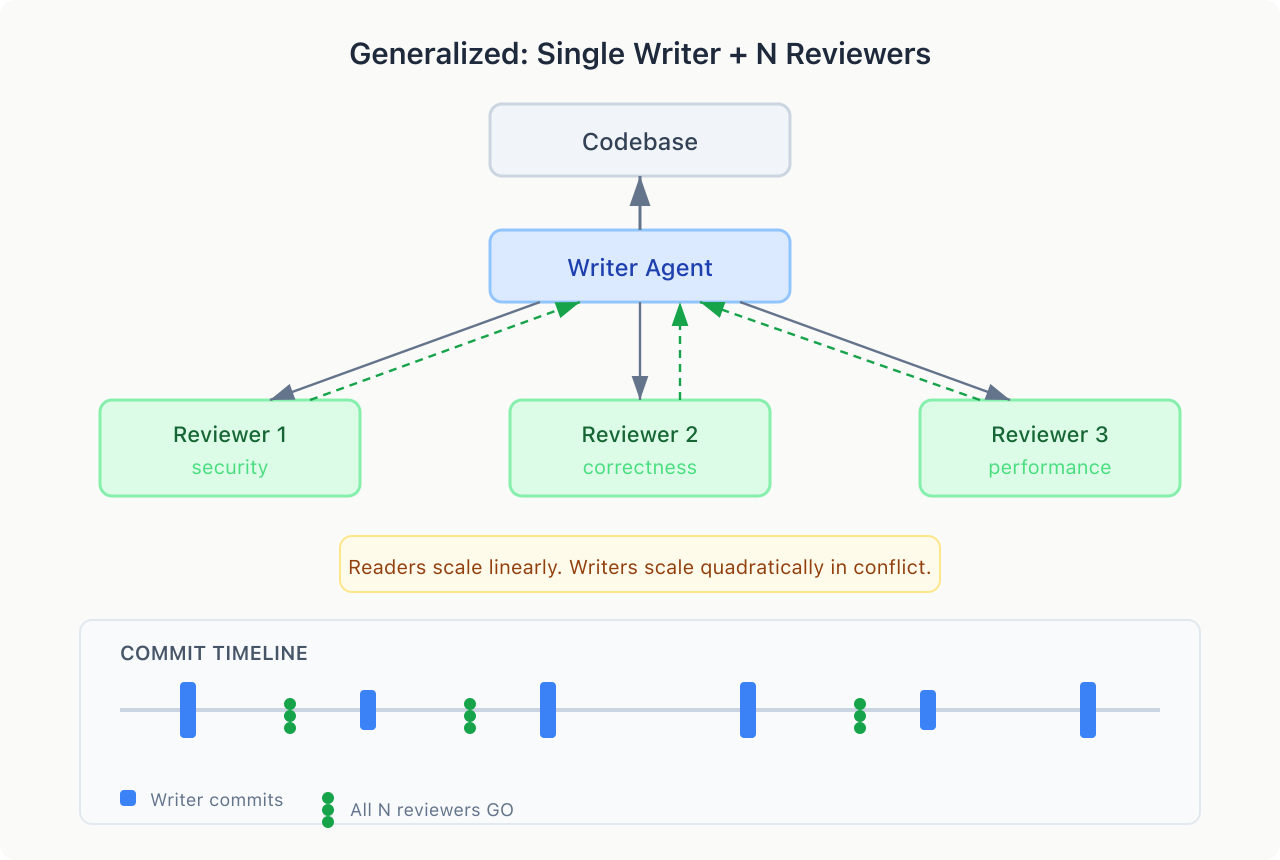
Reviewers are read-only — add as many as you want, no conflict. Each adds a perspective, minimal coordination cost. Readers scale linearly. Writers scale quadratically in conflict.
Review Patterns
Review Patterns (PR and Code)
The single-writer fix controls oscillation, but a single reviewer can still miss things. How you structure review determines what gets caught — and there are trade-offs either way.
Parallel voting (judge panel) is good for catching common issues. Multiple reviewers vote GO/NO-GO independently. When they converge, you have confidence that the general approach is sound — it’s the mean expected quality. Enforced roles (Security, QA, DevOps) improve this further by ensuring each voter scrutinizes a specific aspect. This is your common-case, average-scrutiny pass.
Sequential review compounds scrutiny. Each reviewer reads prior feedback, so later reviewers build on earlier findings. Security flags an issue. Correctness sees it and adds a nil check. Performance sees both flagged a code path and checks whether it’s also a hot loop. This creates compound context — cross-concern interactions that parallel reviewers can’t see.
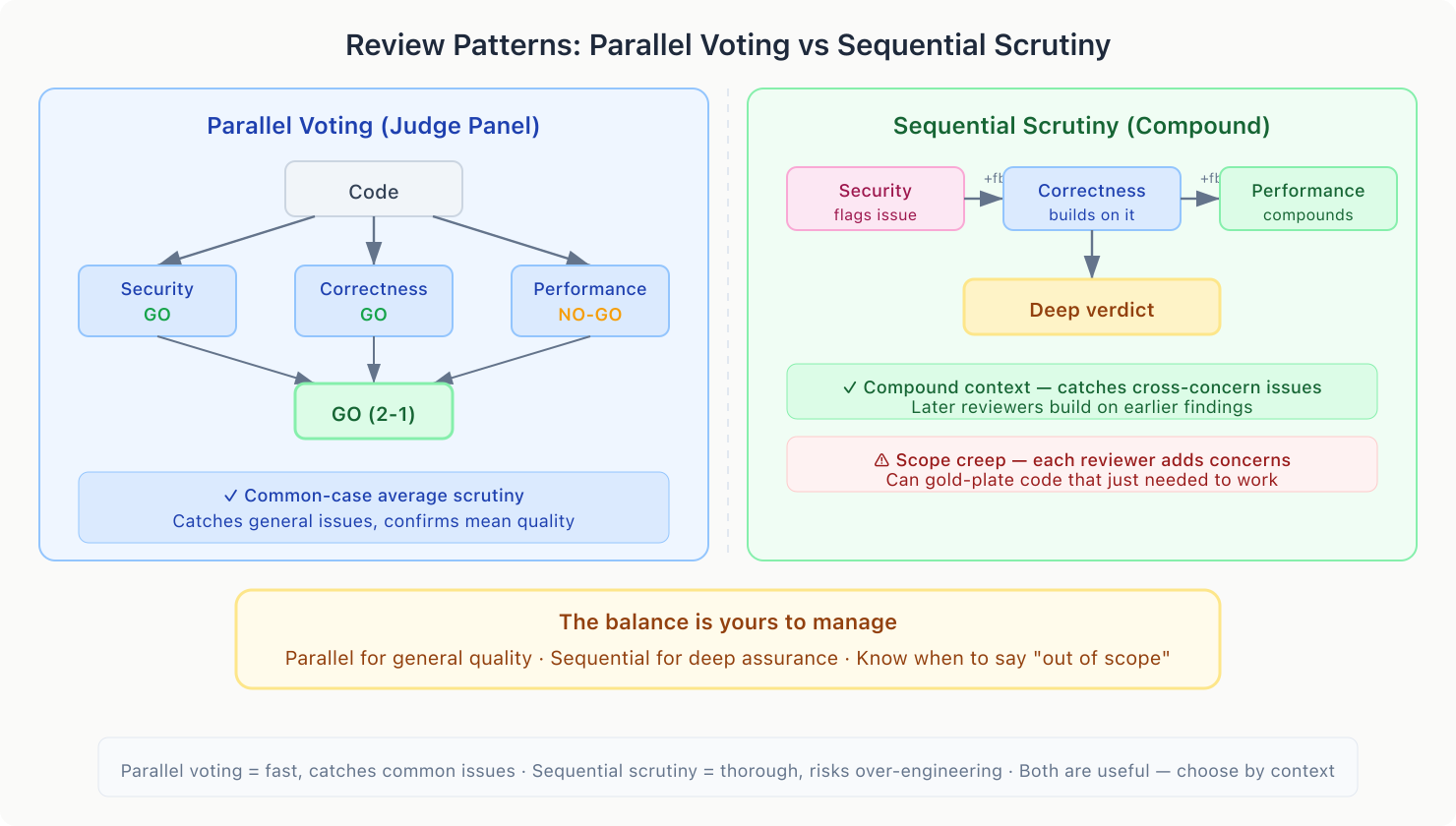
But sequential review has a real downside: scope creep. Each reviewer adds concerns. The security reviewer wants input sanitization. The correctness reviewer wants edge case handling. The performance reviewer wants a cache. Before you know it, the agent is gold-plating a function that just needed to work. Compound scrutiny can compound the work.
The balance is yours to manage. Parallel voting for general quality. Sequential review when you need deep assurance on something specific. And knowing when to tell the reviewer “that’s out of scope, move on.”
Planning Patterns
Exploration and Planning
Review catches errors in code that’s already written. But what about errors in the plan — converging on an approach that misses an entire class of solutions? This is the blind spot problem, and it happens upstream.
Parallel exploration
A single planner gives you a single perspective. If it fixates on microservices, you’ll never see a simpler monolith. Fix: pass the same-ish prompt to multiple agents, then have one synthesize a new plan from the results.
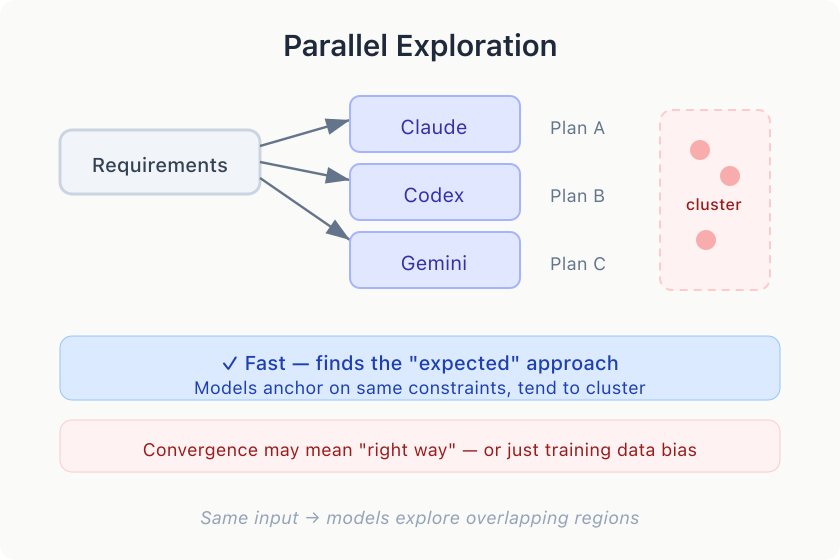
But even with model diversity, parallel planners converge more than you’d expect. They anchor on the same constraints and arrive at variations of the same approach.
This can be good or bad. When models converge, it implies a “right way” — or more precisely, the approach the model training data favors. Example: If 100 internet articles solve a problem in Python and 10 use C++, the C++ approach is less likely to influence the model’s output. That C++ approach might be faster/cheaper/better for your codebase, so nudging the agents is your job as the developer.
Compound exploration
To explore out-of-the-box approaches, try sequential stacking with deliberate divergence — compound planning. Each planner sees the previous proposal and is told to explore something radically different. A proposes monolith. B, knowing that, proposes event-driven. C finds a third option neither considered.
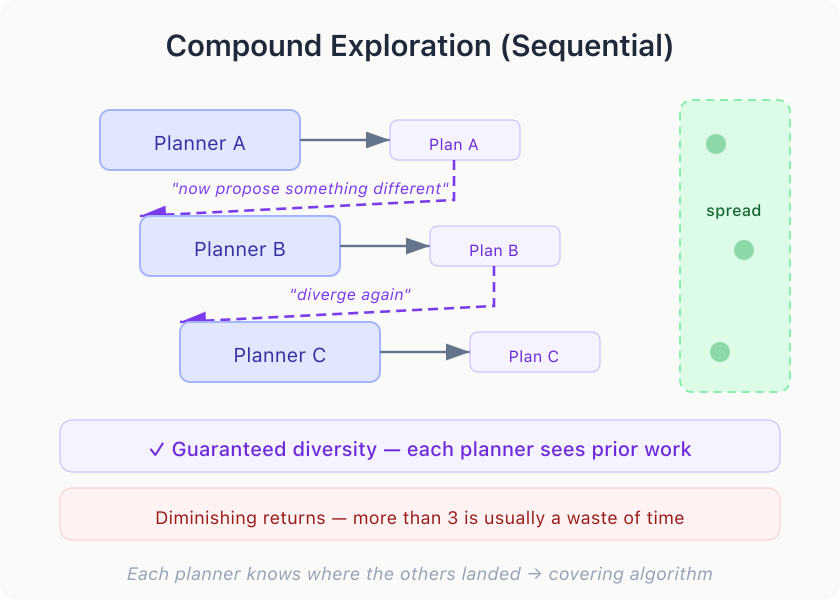
Parallel planning drops probes and observes the model’s distribution. Sequential planning guarantees spread because each planner knows where the others landed. In my experience, three sequential planners explore more than five parallel ones, with diminishing returns — more than three is usually a waste of time.
Synthesis
You now have 3-5 approaches and need to synthesize the one plan to rule them all. My colleagues at StrongDM call this Gene-Transfusion — taking ideas from one context and transplanting them into another. Works across plans, codebases, and models. “I like X from Plan A and Y from Plan C, combine them.”
For complex explorations, synthesize sequentially: incorporate plans incrementally. Each pass asks “what does this new plan contribute that the synthesis is missing?” — it’s simpler than weighing five simultaneously. Sequential synthesis is also a good opportunity to extract tokens from your mind — you’re presented with 3-5 options, so explain which is better and why. Your opinions distinguish an average-of-the-plans solution from the right one.
Meta Patterns
Where the Human Belongs
No agent topology fixes misalignment — agents converging on the wrong thing because the requirements were ambiguous or the context was missing.
Inserting humans at every step bottlenecks agents. Removing humans entirely lets misalignment compound unchecked. The right placement is at phase boundaries where misalignment is expensive: after planning, before implementation, after frontend design, before backend architecture, etc. A wrong plan means all implementation work is wasted. Five minutes of human input here saves hours of rework or agent spinning.
The most important design decision is question format. My initial instinct was to present simple choices: “REST or GraphQL?” That was misguided.
The more open-ended the question, the more valuable the answer.
Ask instead: “What should we know about how this API will be consumed?” As an example, the human might say: “The mobile team is mid-migration to a new client library, so we need both old and new calling conventions for the next quarter. Also, the partner team has been asking for webhook support.”
That answer contains five pieces of information — a migration timeline, a compatibility constraint, a stakeholder request, a strategic opportunity, a time horizon. Closed questions constrain the human to the agents’ solution space — exactly the space that doesn’t need human input.
We build our interview gates with uncertainty scaling: high uncertainty gets 5-7 open-ended questions, low gets 1-2. Every question includes a skip option. “The human chose not to intervene” is meaningfully different from “the human was never asked.”
Simple decisions go in CLAUDE.md, AGENTS.md, or your README.md — treat them like committed code. Interviews address the messy middle, where you don’t know what you care about yet and the agent’s job is to help you figure it out.
Orchestrator and Teams
At scale, multiple writer-reviewer pairs can oscillate at the decision level — not conflicting code, but conflicting assumptions about interfaces, data shapes, and sequencing.
The orchestrator model: one agent coordinates, the others execute. The orchestrator assigns work, routes information, and resolves conflicts. Each subagent owns a concern and is the sole writer within it. No two agents write to the same files.
All communication flows through the orchestrator. Subagents never talk directly. This is deliberate: if the backend agent tells the frontend agent “use this endpoint” and the frontend agent replies “that shape doesn’t work, change it” — now you have two agents negotiating a shared interface. Without a tiebreaker, they loop. The orchestrator decides: “The API contract is {name, email, avatar_url}. Backend: implement it. Frontend: consume it. This is not a negotiation.”
Two communication modes: direct (orchestrator to one subagent: “here’s the API contract the frontend needs”) and broadcast (orchestrator to all: “we’re switching to GraphQL for new endpoints”).
This scales linearly. Hub-and-spoke gives you N connections for N agents. Fully connected gives you N*(N-1)/2. At ten agents, that’s ten vs forty-five. The orchestrator pattern doesn’t just simplify coordination — it makes large agent teams possible.
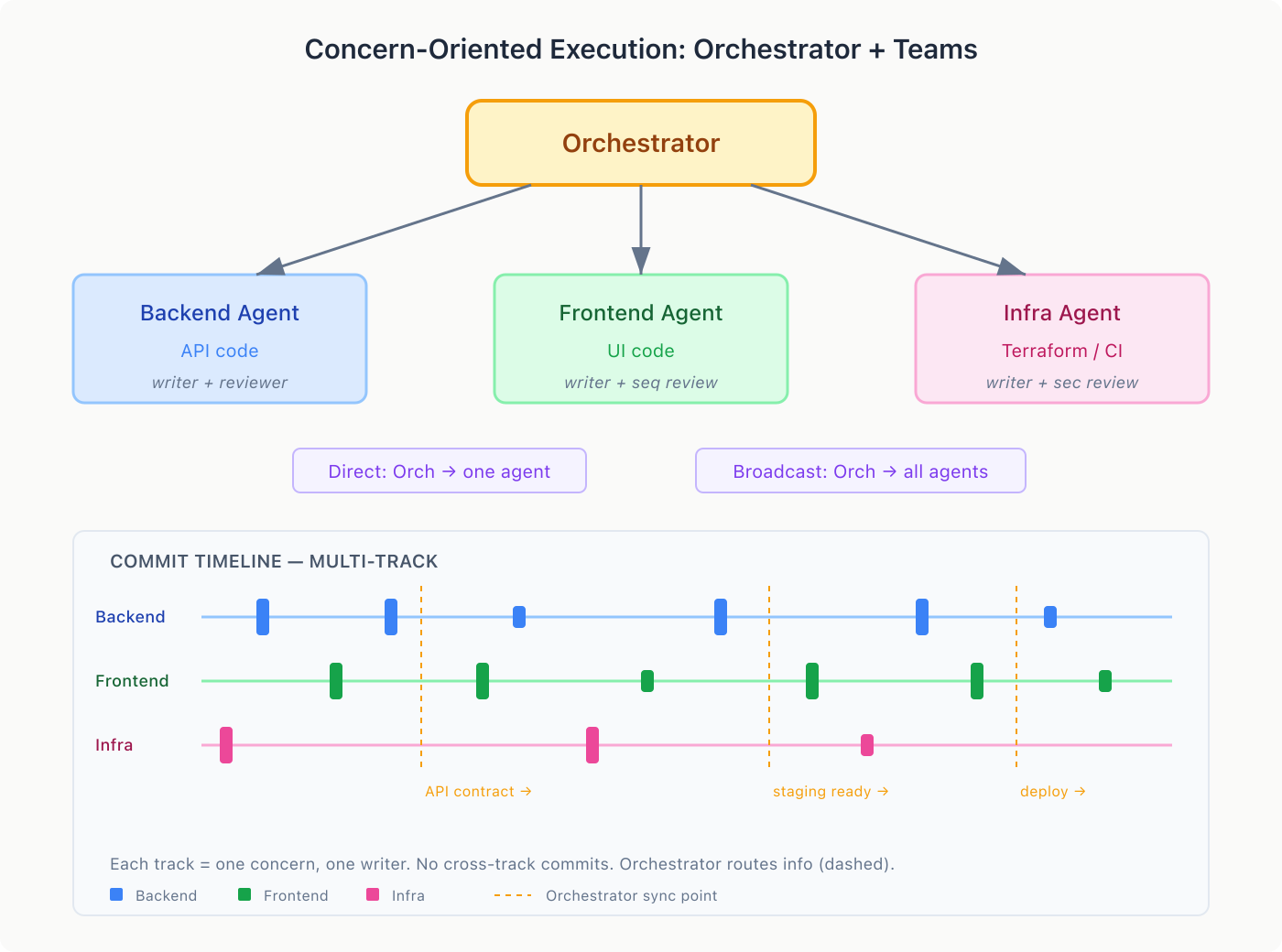
Each subagent internally uses whatever pattern fits: the backend agent might run a writer-reviewer loop, the infrastructure agent might use sequential security review. The orchestrator is a composition layer — it doesn’t replace the other patterns, it provides the structure for multiple instances to run concurrently. You define the patterns for each subagent role based on what you need to see to have confidence. I built this pattern separately, but Anthropic arrived at the same thing with agent teams in Claude Code — great minds think alike?
Adversarial Validation
Every pattern above controls error during production of code — writing, planning, reviewing. But there’s a final error mode: agent confirmation bias. Agents that wrote the code and agents that reviewed the code share the same assumptions about what “correct” means. They can pass each other’s checks and still be wrong. You need something outside the system — a separate environment, a separate codebase, run by a separate agent, with the explicit goal of breaking the application.
Separation is an information boundary — validation doesn’t live in the same repo, doesn’t get modified by the same agents, and is forced to test against the specification, not the implementation.
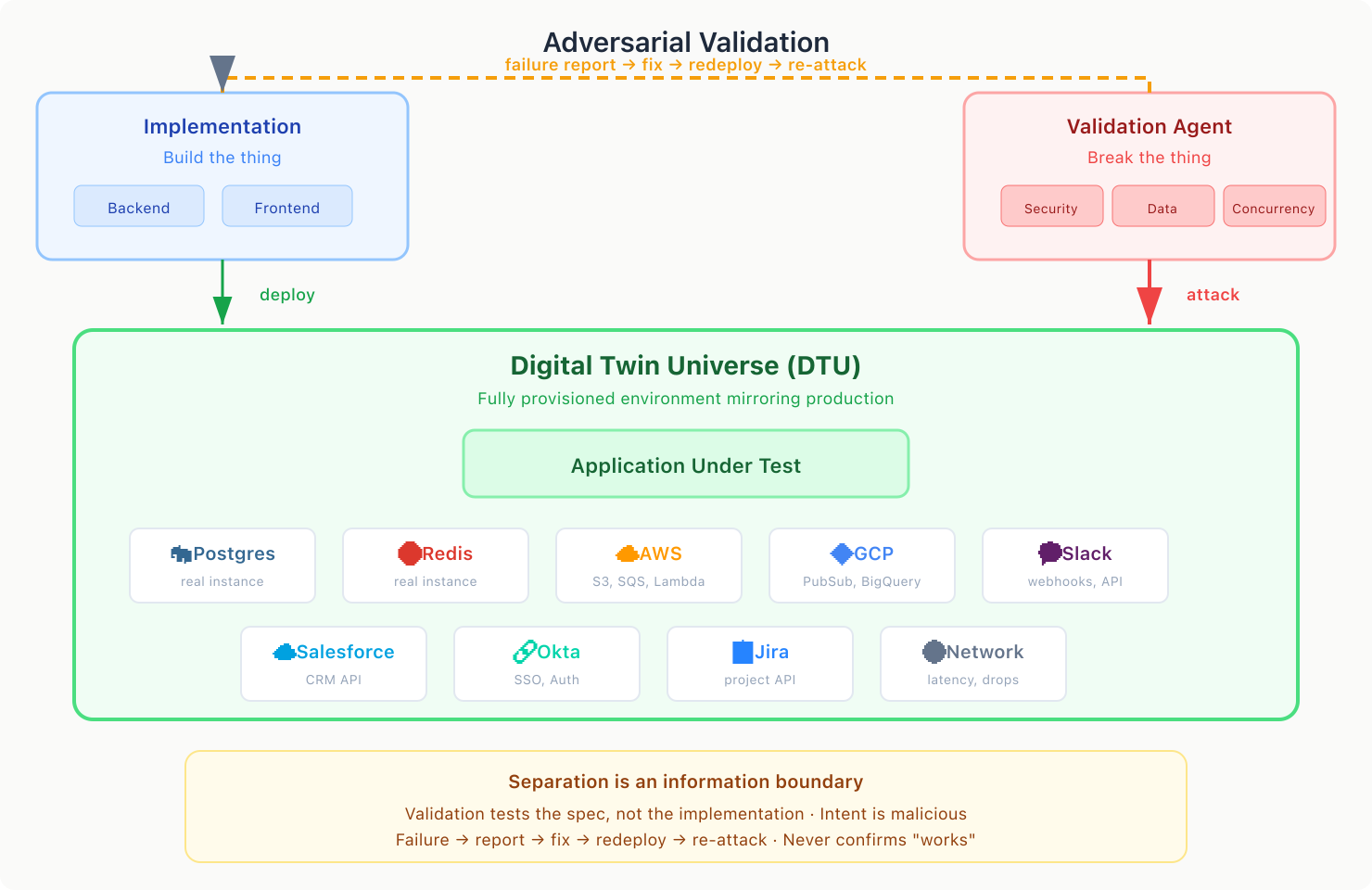
The validation environment should reproduce production’s failure modes as closely as possible— real Postgres, not in-memory SQLite; realistic data volumes, not three rows; network latency, not localhost. At StrongDM, my colleagues in the dev-agent lab coined Digital Twin Universe (DTU) — fully provisioned environments that mirror production with synthetic services. Entire applications “interpolated“ via their public SDK: real databases, real network configs, real dependencies, real SaaS APIs. Frankly, do this first — it works and it’s better than unit tests. The implementation agent gets the same real feedback that your users will get.
The validation agent’s job is to break the application, not confirm it works. Not “does login work?” but “can I bypass login? Can I replay a revoked token? What happens when I log in from a suspended org during a database failover?” The intent is malicious — attacker, confused user, flaky network, and race condition, all at once.
This adversarial approach needs structure: dimensions (security, correctness, data integrity, concurrency, integration) with dozens of scenarios per dimension, each a specific, reproducible attack run against the real environment. When validation finds a failure, it reports what broke. The implementation pipeline fixes it. The validation agent re-attacks. It never confirms the code works — just that it hasn’t broken it yet. That’s the error mode confirmation bias creates, and adversarial validation is the only pattern here that addresses it.
The Error Control Ladder
Each pattern in this article addresses a specific error mode and they build on each other:
Single writer - This pattern controls oscillation by preventing two agents from repeatedly undoing each other’s work.
Sequential review + compound exploration - This pattern controls blind spots by reducing the chance that one perspective misses entire classes of issues or solutions.
Human interview gating - This pattern controls misalignment by stopping agents from confidently building the wrong thing.
Orchestrator - This pattern controls cross-concern conflict by coordinating independent teams that might otherwise make incompatible assumptions.
Adversarial validation - This pattern controls confirmation bias by preventing agents from passing each other’s checks while still being wrong.
The ladder is additive. Start with single-writer. Layer on sequential review when blind spots bite. Add compound exploration when plans keep missing options. Insert interview gating when you ship the wrong thing. Scale to an orchestrator when cross-concern conflicts emerge. Bring in adversarial validation when you need confidence beyond code review.
Across all of these, the same principles show up:
Parallel averages out noise — gets you closer to the expected approach. Provides unbiased agents
Sequential introduces feedback that either tightens error or explores the design space. Injects feedback towards a specific objective.
Pull developer opinions — find ways to extract what you know. Communicating your intent is the bottleneck.
Adding agents does not eliminate the Part 1 failure modes. It reshapes them. These patterns are meant to manage those new forms. The craft lies in knowing which one to apply, at what moment, while making your reasoning legible in the terminal.
In Part 3, we’ll dig into the fundamental feedback signals themselves — what to measure, how to close the loop, and how to tune these patterns once they’re running.